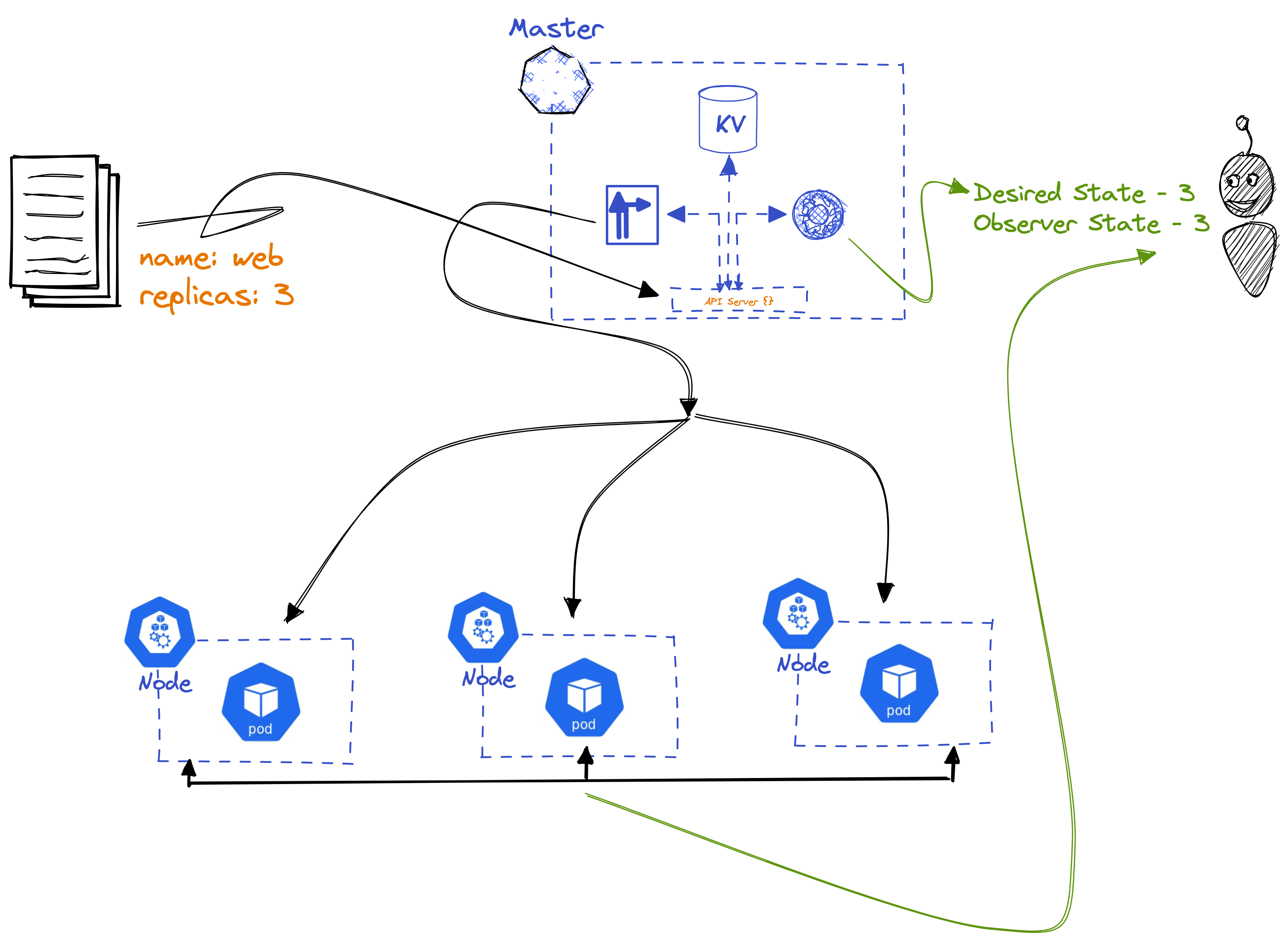
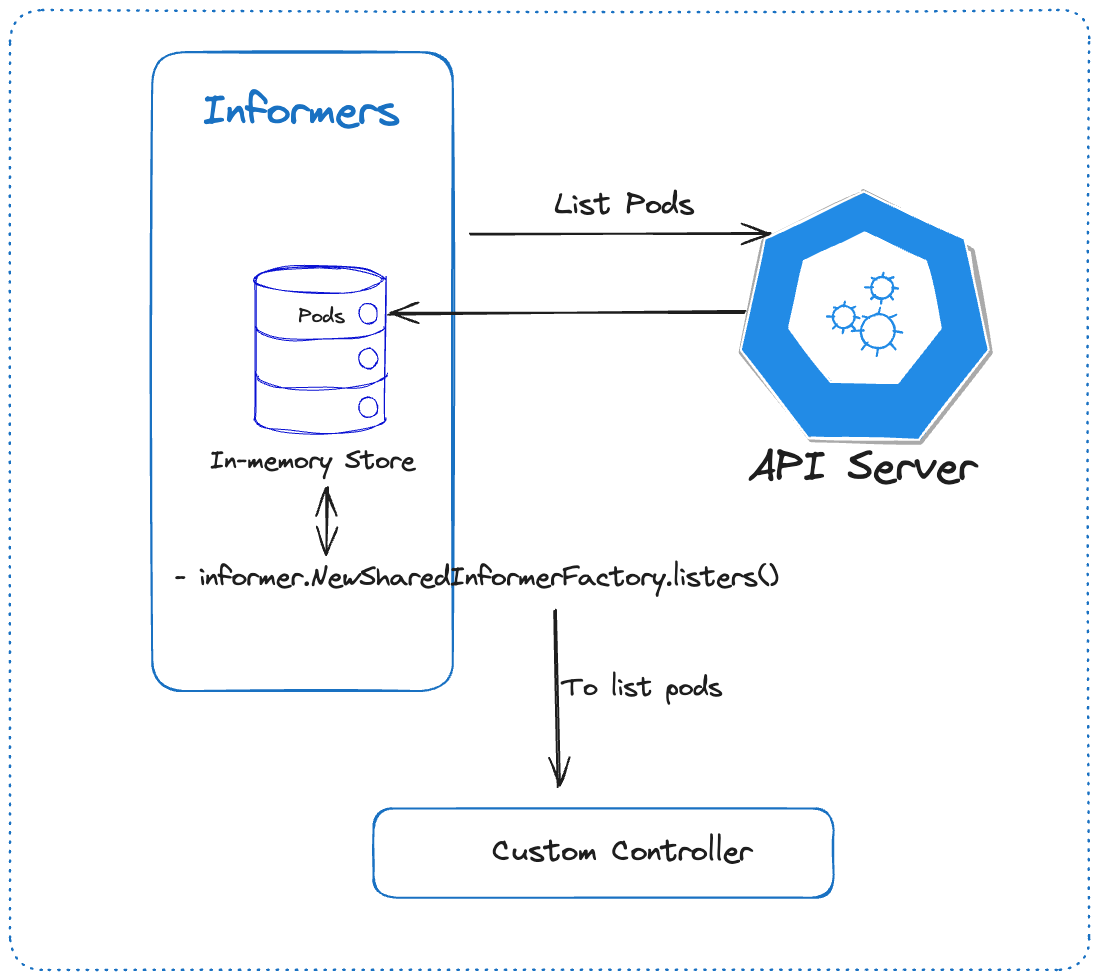
Generally when you want to create, list or delete pods or any resource within a Kubernetes Cluster. This is how the workflow looks like at a high level

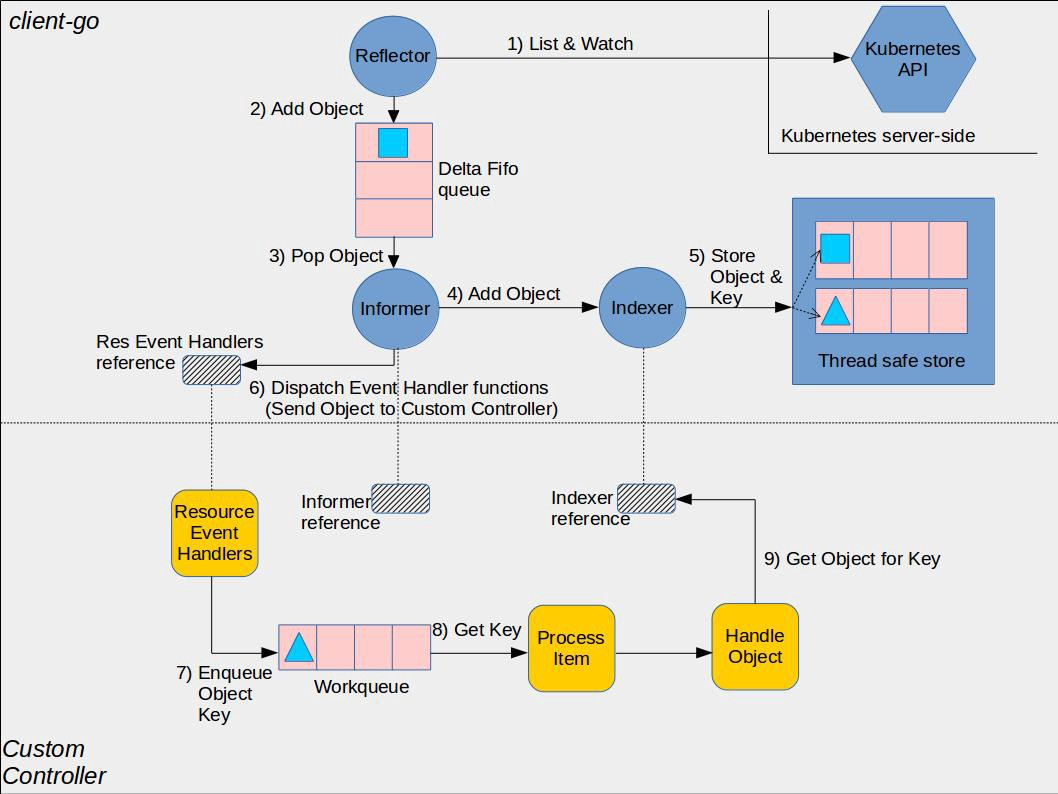
Digging little deeper in the above workflow looks something like this
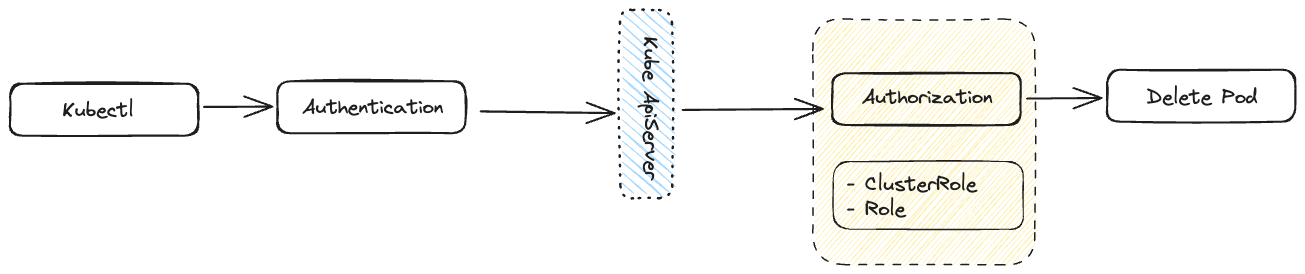
- With Kubectl, a user makes the request to the Kubernetes Api server.
- Kubectl makes use of kubeconfig file present at ~/.kube/config. The config file contains the client certificates for authentication, API server address, user who is making the request and few other details
- The client Certs present within the kubeconfig file are checked, if they are valid the request goes through.
- Post authentication, what kind of permissions the user has is checked by the Kube ApiServer. The permissions are defined by clusterRoles or Roles objects in Kubernetes
- If the user has delete verb associated with their role for a pod resources. The operation is carried out. A cluster role can only allow operations(Verbs) such as create, delete, list and control over resources such as pods, secrets, Configmap etc but do not controls such as Allow control over images being used from a certain registry Container running as root user Control over certain container capabilities

Def - Admission controllers provides us with some level of control on what to do with the request before it is being executed. With admission controllers, you can not only validate the kind of operation/request but also change or perform additional operations before the pod is created
List of known built in Admission controllers at present - https://kubernetes.io/docs/reference/access-authn-authz/admission-controllers/#what-does-each-admission-controller-do . The Kubernetes document contains detailed information about these admission controllers so I won't be mentioning them here.
Admission controllers are of two different types
- Validating Admission controllers
- Mutating Admission controllers
Validating Admission controllers Take example of PodSecurity Admission controller, the PodSecurity admission controller checks new Pods before they are admitted, determines if it should be admitted based on the requested security context and the restrictions on permitted Pod Security Standards for the namespace that the Pod would be in. The Pods security standard has certain labels which define the scope of allowed or disallowed values from security context and if the pod manifest violates the Pod Security Standard restrictions then PodSecurity Admission controllers kicks in and rejects the admission of the pod.
Mutating Admission controllers Lets take an example of DefaultStorageClass admission controller, this admission controller observes creation of PersistentVolumeClaim objects that do not request any specific storage class or missed adding the type of storage class. It automatically adds a default storage class to them. This way, users that do not request any special storage class do not need to care about them at all and they will get the default one. This way it changes or updates the request before creating the actual object.
Note: If both the type of controllers have been added in the object creation then Mutating admission controllers are invoked first and then validating admission controllers kick in if required so that any change made by the Mutating admission controllers can also be validated.
External Admission Controllers: Kubernetes has already provided with bunch of controllers but what if you want to have admission controllers which you control. You control what validations it should do or mutations it should do before creating the actual resource. Kubernetes does have a support for that as well.
Presenting,
- MutatingAdmissionWebhook - https://kubernetes.io/docs/reference/access-authn-authz/admission-controllers/#mutatingadmissionwebhook
- ValidatingAdmissionWebhook - https://kubernetes.io/docs/reference/access-authn-authz/admission-controllers/#validatingadmissionwebhook