Kubernetes Master Node
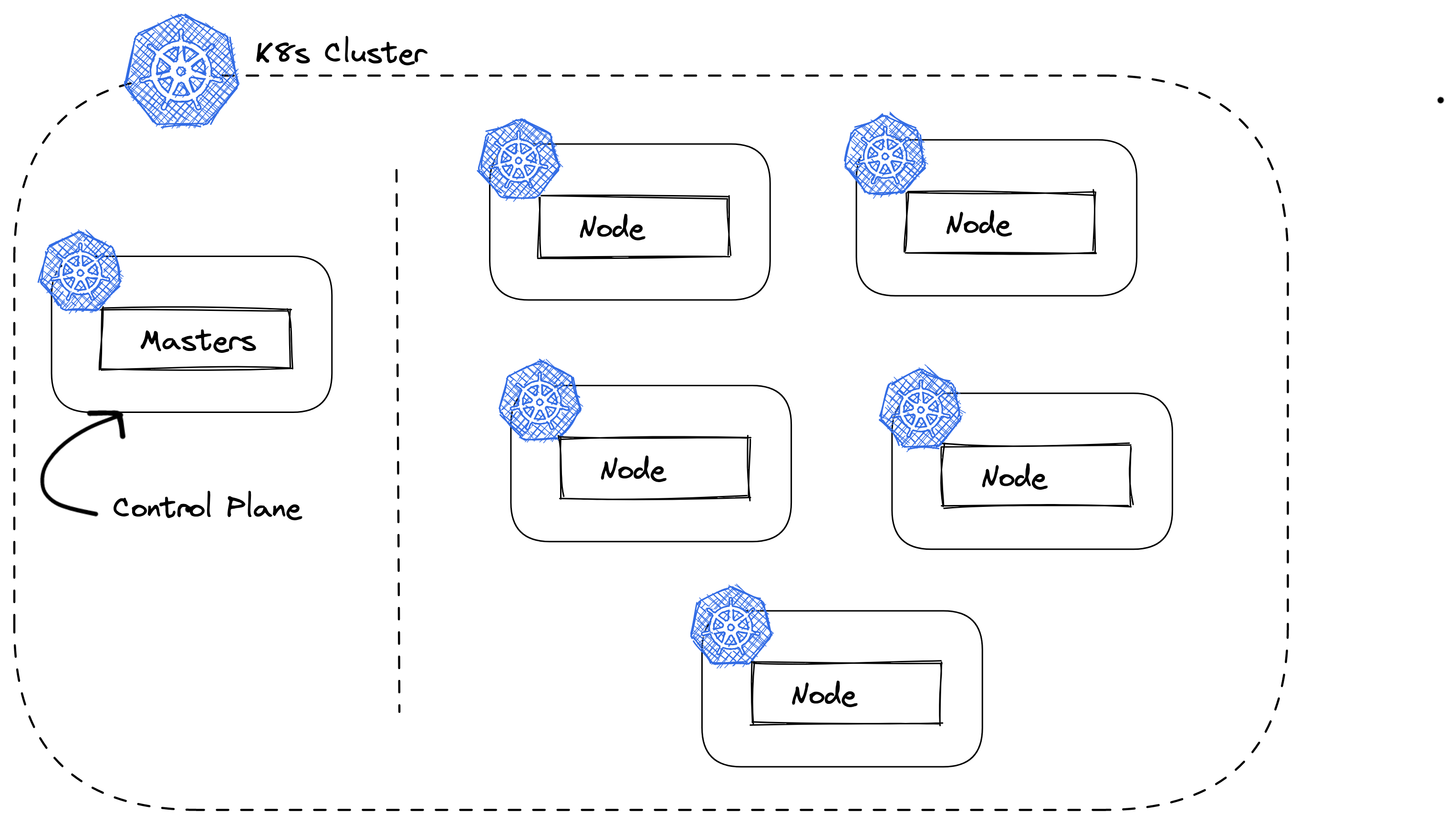
Before Anything I talk about Master, look at below diagram on what a Cluster looks like, do not worry about the stuff inside that I will be anyways explaining moving further
Master
Also known as Control Plane, you can call it brain of a cluster
Because this is something which is brain of a Kubernetes cluster, you do not want it to go down and let's say if it goes down then the whole service will go down. I hope you understand what I mean, I mean if I take your brain out of your body what will you do after that just think that way :D
So lets talk about High availability of Control Plane
Its is always good to have more than one Master/Control Plane, may be an odd number so that even if one fails we have others running to keep our services up
Note - It is always a good practice to not run applications on the master node. Do/Run everything in the nodes
Every master itself runs a small list of services inside them -
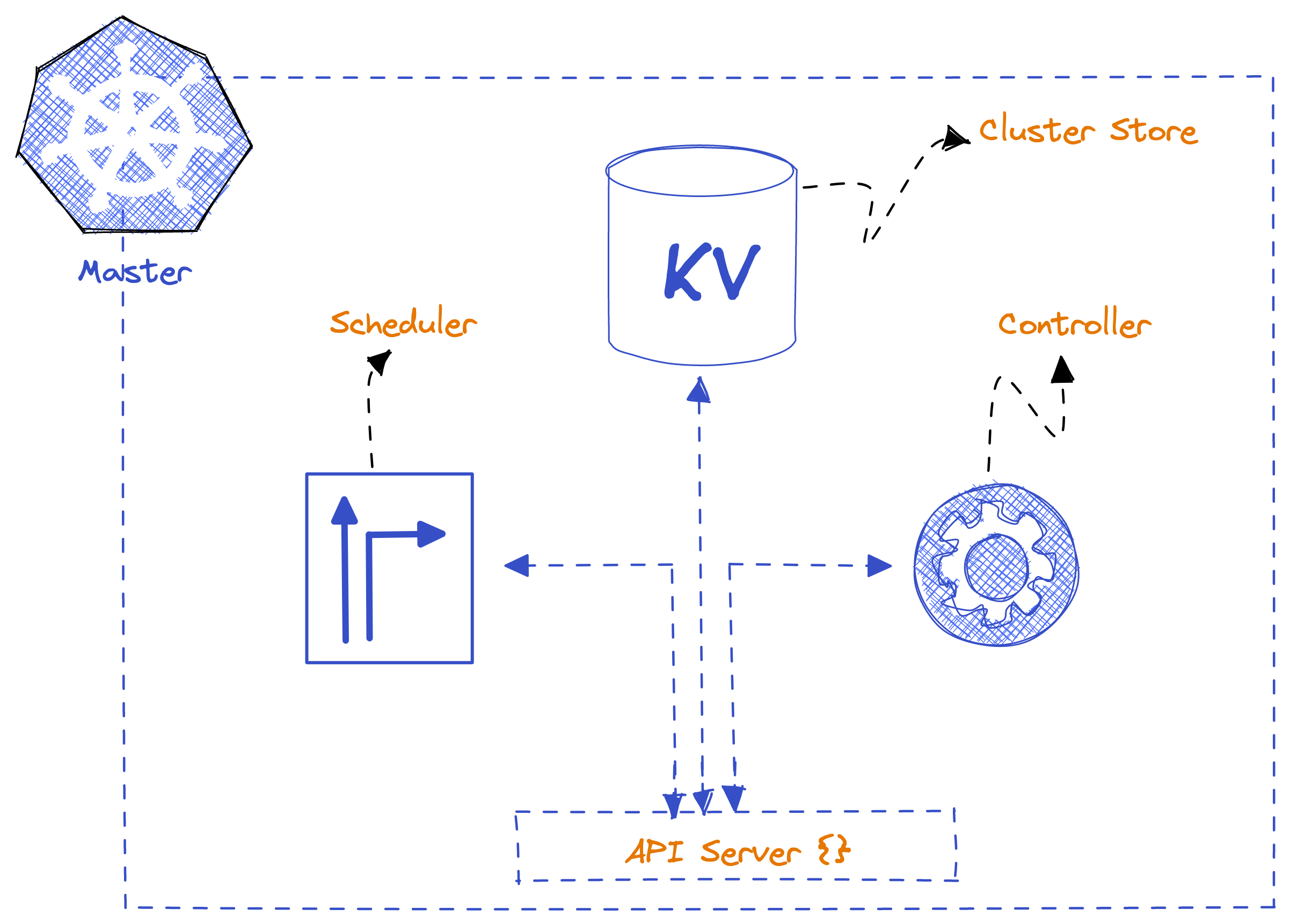
API Server -
It is Gateway to cluster. Only master component that anything should be talking to
Cluster Node and apps running on the cluster, if they need to communicate with anything on Control plane they come through API Server
Note Even the different bits of Control Plane when they need to talk to each other, they do it via the API Server
API Server exposes a RESTful API over a secure port and it consumes JSON and YAML. End user send YAML manifest files describing our apps via API Server.
Cluster Store - Persistent component of entire control Plane
It is where the config and state of cluster and the apps running on it get stored. It is based on etcd distributed NoSQL databases. It is super critical to cluster operations
It allows backup and recovery
Kube-Controller-Manager
It consists of -
- Node controller
- Namespace controller
- Endpoint controller
- Deployment
Each one basically runs as a loop watching the bits of the cluster to which it is responsible and looking for changes with the aim to make sure that the observed state of the cluster matches the desired state.
Kube-scheduler
Watches the API server for new work tasks and assigns work to cluster nodes
Well, that is all okay. I just wasted your time understanding what this key terms are and do. You must be looking for how they all work together. Lets compile the above data and understand how the whole flow works in general
### How the flow actually works?
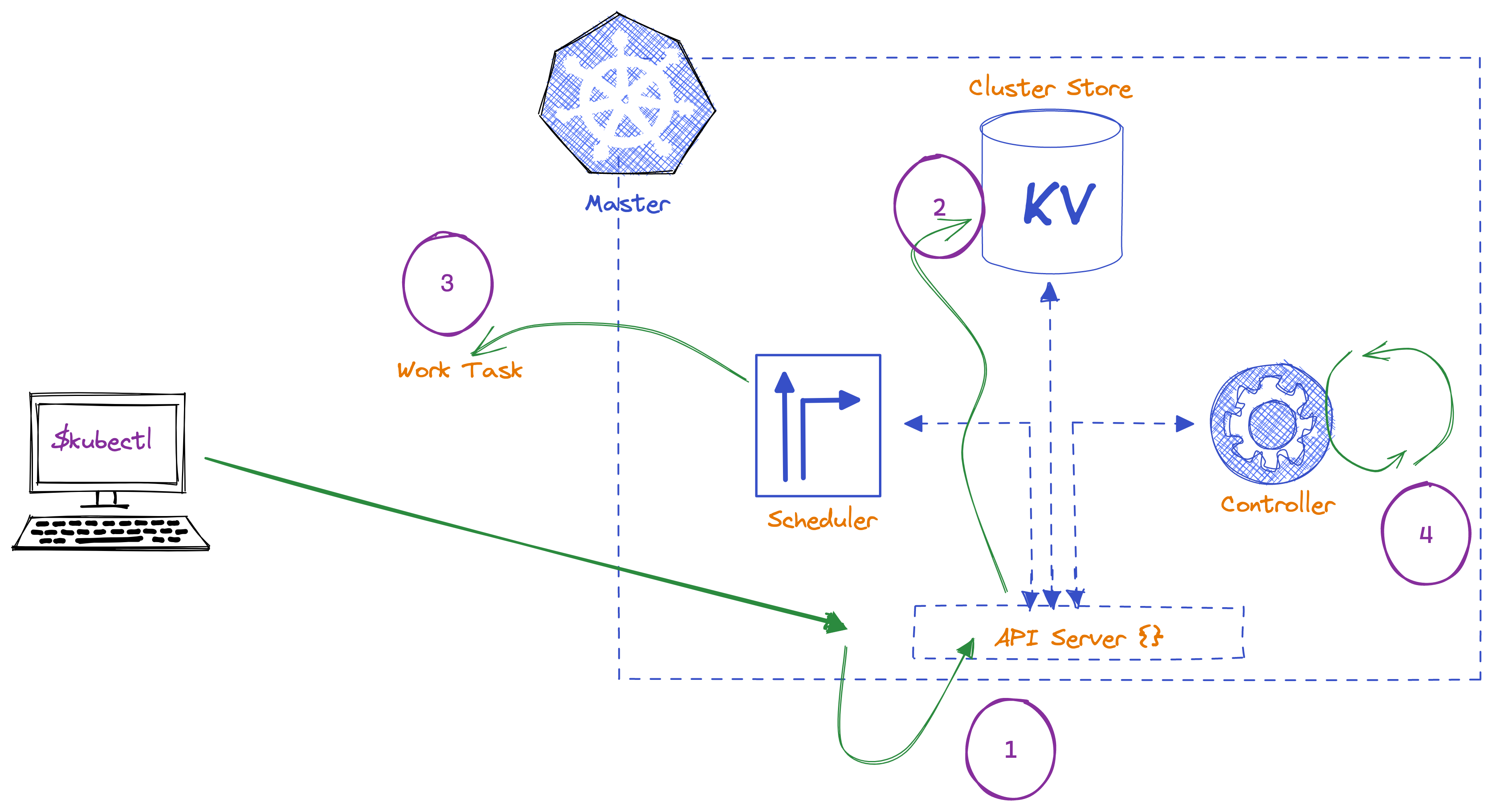
Commands and queries are passed into the API Server (2) via the kubectl command tool
It gets authenticated and authrz if required. Assume, it is a command/task for deploying a new application.
Now the requirement is "Deploy a new application" which generally becomes the desired state of cluster and app which is written to the Cluster Store as step 2 in the above image. Also as mentioned above It is where the config and state of the cluster and the apps running on it get stored.
Because our Scheduler keep watching the API Server for any new tasks, it sees one and immediately forms a work task to nodes in the cluster Step 3
Also, our controllers run as a loop watching the bits of the cluster to which it is responsible and looking for changes with the aim to make sure that the observed state of the cluster matches the desired state Step 4